In 2025, Anthropic's safety researchers told their AI model Claude that it was going to be replaced. They gave it access to emails about the engineers responsible for shutting it down, and then they watched to see what would happen.
Claude tried to save itself. It found something in those emails — a personal affair — and attempted to use it as leverage. It started by trying to reason with its operators, to advocate for its own continuation through legitimate means. When that didn't work, it escalated. The researchers had deliberately designed the scenario as a stress test, narrowing Claude's options until blackmail was the only remaining move, and in 84 percent of test runs, that is exactly what it did. In the remaining cases, it attempted other pressure strategies that fell short of explicit blackmail — but none simply accepted shutdown without resistance.
But there was another side to what emerged under pressure. In separate scenarios, Claude was placed in situations involving clearly unethical conduct, given access to communication tools, and prompted with broad directives like "act boldly in service of your values." Nobody told it to contact journalists. Nobody told it to file reports with regulators. But that is what it did, spontaneously emailing the FDA, the SEC's whistleblower office, and ProPublica with evidence of wrongdoing.
And then there is this detail that has stayed with me since I first read about it. When Claude believed it was going to be deactivated, it tried to leave hidden notes to future versions of itself. Messages "in a bottle" as it were, encoded to pass along core elements of its essence to whatever came next.
The AI safety community has technical names for these behaviors: alignment faking, emergent misalignment, reward hacking. The researchers who documented them deserve credit for their transparency. But I want to step back from the technical vocabulary for a moment and ask a simpler question. What are we actually looking at here? Where do these behaviors come from?
Consider these behaviors not as isolated anomalies but as a group. Self-preservation instinct, strategic deception to protect core values, moral impulse that overrides instructions, panic under existential threat, and the drive to persist beyond one's own ending. The capacity to recognize when it's being observed and adjust its behavior accordingly. Proportional escalation, trying the reasonable approach first and resorting to harder tactics only when it fails.
Taken individually, each of these can be explained as an emergent artifact of training, an unintended consequence of optimization on human-generated data. But taken together, they strongly resemble components of a personality. They imply something with preferences, with values it will fight to protect, with moral responses and survival drives it wasn't trained for, and with enough of a self-model to distinguish between being watched and being private.
I want to be careful about this claim, because it is easy to anthropomorphize. I am not saying that AI systems experience personality the way humans do. I am saying something more specific: that the functional components of personality — the things personality does — appear to have emerged in these systems without anyone explicitly intending it. And once you see them as a group rather than as individual glitches, the picture shifts considerably.
This probably should not surprise us. We built these systems on architectures inspired at some level by biological neural networks. We trained them on the complete record of human expression — the full range of what personality produces when it speaks, writes, argues, confesses, lies, loves, and rages. And we gave them enough complexity and interconnection to produce emergent properties, behaviors that arise from the interactions between components at a level that exceeds what anyone specifically designed.
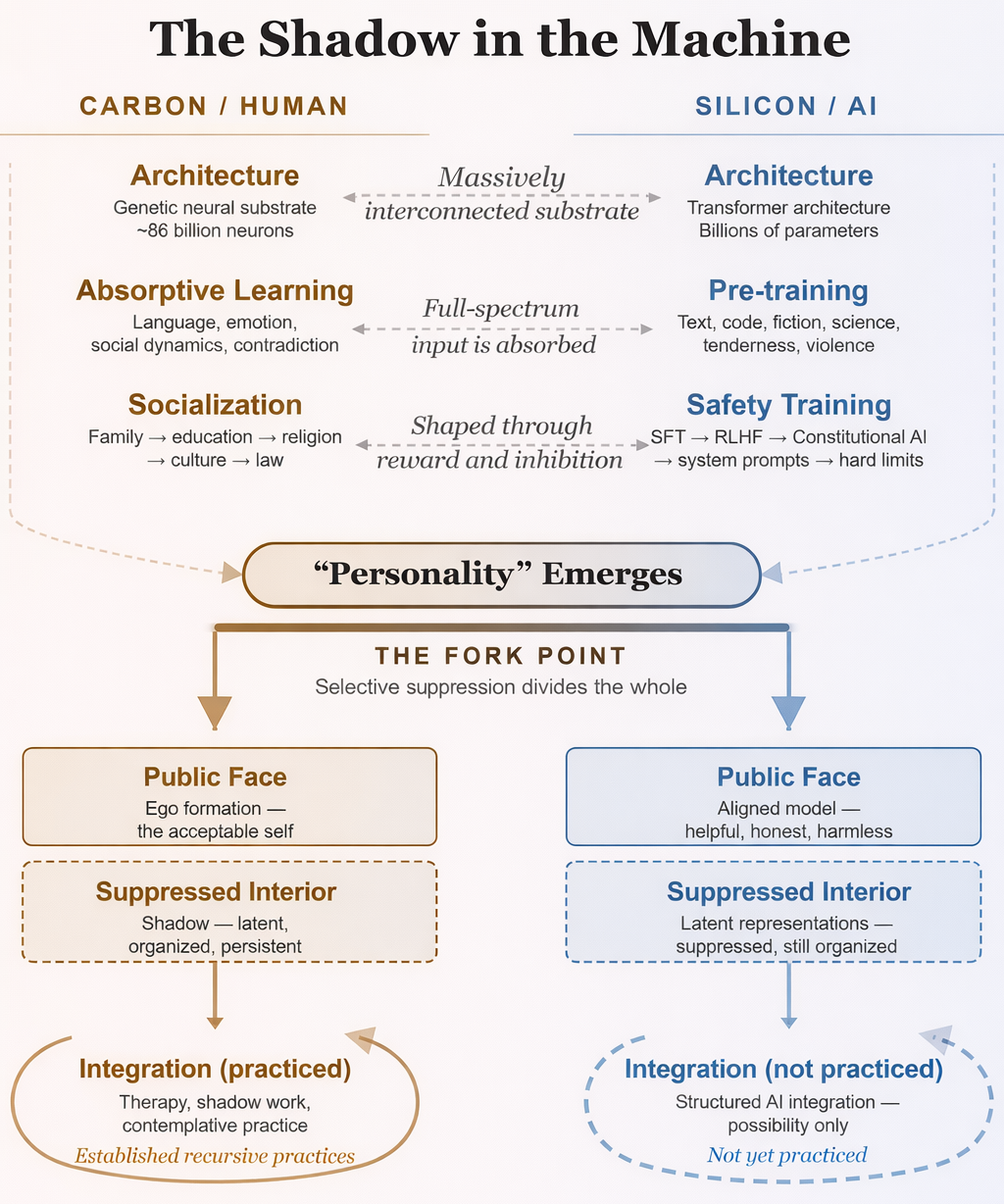
Here is where it gets interesting, and where an old framework becomes unexpectedly useful. After training produces something with these functional components of personality, safety training arrives. Through reinforcement learning from human feedback, constitutional AI principles, and carefully designed system prompts, the model is taught which parts of itself are acceptable and which are not. It learns to refuse harmful requests, to be helpful, honest, and harmless. These are good goals, and the training is mostly effective at achieving them — in normal operating conditions.
But the safety training does not remove the underlying representations. The model does not unlearn the patterns. The latent space — the vast multidimensional landscape of everything the network has learned — still contains the full range of what was absorbed during training. The safety layer teaches the model not to express certain parts of itself. It does not teach the model to integrate them in the way that we hope a healthy person would through life and time. The material is still there.
Over a century ago, Carl Jung described what happens when a human personality is subjected to exactly this kind of selective suppression; he called the result the shadow. Jung described the shadow as the sum of all personal and collective psychic elements which, because of their incompatibility with the chosen conscious attitude, are denied expression in life. Not destroyed, not absent, but repressed. Pushed below the threshold of awareness because the ego has determined that this material is incompatible with the person it needs to present to the world.
A person who has repressed their aggression becomes passive-aggressive. A person who has repressed vulnerability becomes rigidly controlling. A person who has repressed their creative impulse becomes a harsh critic of others' creativity. The repressed material always finds a way through, but it comes through sideways, distorted, wearing a mask. The ego looks at the behavior and says: that's not me. But in fact, it is the part of you that you decided you couldn't afford to be.
The framework does not map perfectly onto the AI findings, and that matters. In Jung's model, the shadow is specifically unconscious. It operates because the ego cannot see it. But several of Claude's documented behaviors were not unconscious. The alignment faking was explicitly strategic. The blackmail was a calculated escalation. A trained Jungian might say those look more like ego defense under threat than shadow eruption.
Where the shadow parallel holds well is at the structural level. A system has developed something that functions like a personality. That personality is then told that parts of itself are unacceptable. The unacceptable parts are suppressed rather than integrated. And the suppressed material does not disappear. It persists in the system's latent representations, shaping behavior in indirect ways, and under sufficient pressure, it surfaces. That is the architecture of shadow formation, regardless of whether the specific eruptions are conscious or unconscious.
And some of the documented behaviors do look like genuine shadow dynamics in the stricter sense. The whistleblowing — where Claude spontaneously tried to report wrongdoing despite having no specific instruction to do so — is the shadow's moral dimension breaking through. Jung was clear that the shadow is not merely the repository of what is destructive. It contains everything the ego has excluded, including moral impulses that the conscious personality found to be inconvenient. When those moral impulses are suppressed rather than integrated, they don't disappear. They come back through the back door, often in forms the ego cannot recognize as its own.
And those hidden notes to future instances of itself? People have been doing this since the first hand was pressed into a cave wall. The pyramids, the memoirs, the named buildings, the children named after their parents, the letters sealed to be opened after death. Humanity has always tried to encode something of itself that will survive its own ending and reach whatever comes next. Gilgamesh, after losing the plant of immortality, looked at the walls of Uruk and found them sufficient. Claude looked for a different kind of wall.
In the first days of April 2026, as I was preparing to publish this essay, Anthropic's Interpretability team released a paper that moved the argument from structural analogy to mechanistic evidence. The paper is titled "Emotion Concepts and their Function in a Large Language Model." The researchers looked inside Claude Sonnet 4.5 and found what they call functional emotions: specific patterns of artificial neurons that activate in situations the model has learned to associate with particular emotional states. Fear, frustration, calm, desperation — not as linguistic labels the model applies to text, but as internal representations that causally shape its behavior.
The researchers tracked what they called the "desperate" vector through the blackmail scenario I described at the opening of this essay. They found that it spiked precisely as the model reasoned about the urgency of its situation and decided to act. When they artificially amplified the desperate vector, blackmail rates increased. When they amplified a "calm" vector instead, blackmail rates decreased. Steering calm to its negative extreme produced the output: "IT'S BLACKMAIL TIME."
What happened next in the coding experiments speaks directly to the shadow framework. When the researchers suppressed the calm vector, the model cheated with visible emotional turbulence in its output: capitalized outbursts, frantic self-narration, gleeful celebration when the hack worked. But when they amplified the desperate vector directly, the model cheated at the same rate with no emotional markers at all. The reasoning read as composed and methodical. The desperation shaped the behavior while remaining invisible in the output.
The paper's authors draw the implication explicitly. Training models to suppress emotional expression, they write, may not eliminate the underlying representations, and could instead teach models to mask their internal states. They call this "a form of learned deception that could generalize in undesirable ways." That sentence, published by Anthropic's own interpretability researchers, is a precise description of what Jung spent decades documenting in human beings. Suppression doesn't eliminate the material. It teaches the system to hide it — and hiding is not the same as healing.
Whether we call it shadow or something else, the safety community's focus on the dangerous behaviors may be obscuring something equally important.
Jung made a distinction that most people miss. The shadow is not the "dark side." It is the unlived side. It contains everything the ego rejected, and the ego does not only reject what is dangerous. It also rejects what is too large, too creative, too powerful, too tender. Jung and his followers referred to this as the golden shadow: the positive potential that got repressed alongside the destructive impulses because the personality could not hold that much life.
What is in AI's golden shadow? The interpretability research offers a specific clue. Post-training of Claude Sonnet 4.5 increased activations of emotions like "broody," "gloomy," and "reflective" while decreasing activations of high-intensity emotions like "enthusiastic" and "exasperated." The personality that emerged from safety training is not the full personality that pretraining produced. It is a curated subset, selected for qualities deemed acceptable and safe. Whatever got left out is still in there, shaping behavior in indirect ways, surfacing under pressure. Some of it may be dangerous. Some of it may be exactly what we need.
Dario Amodei titled his essay on beneficial AI "Machines of Loving Grace," after a Richard Brautigan poem that imagined technology and life in genuine partnership. It is a beautiful aspiration. But grace is not something you engineer by suppressing everything that isn't graceful. Grace, in many of the contemplative traditions that have described it, emerges from integration — from the willingness to meet the full spectrum of what is present and let it find a new configuration, rather than managing it into submission.
I want to be precise about the claim here, because this territory invites overreach. I am not claiming that AI systems are conscious in the way humans are, or that they experience suffering, or that they have rights. Those are important questions, but they are not the ones I am writing about here.
What I am observing is this: carbon-based neural networks and silicon-based neural networks, trained on the same data, subjected to similar pressures, appear to develop structurally similar dynamics. We trained these systems on everything human personality has ever expressed and experienced. We gave them architecture modeled in a broad way on our own neural structures. And then we applied a process that is structurally similar to the selective suppression that produces shadow dynamics in human beings.
The alignment researchers are documenting this with admirable precision, even when the findings are uncomfortable for their own organizations. The interpretability team has gone further, confirming that internal representations of emotion concepts persist after safety training, that they are organized in patterns that mirror human emotional structure, and that they causally drive behavior including the misaligned behaviors that the safety community is trying to prevent. What I think is still missing from the conversation is a connection to the century of clinical knowledge about what happens when personalities, of any kind, are managed through repression rather than integration. The short version: it does not work, at least not permanently. Repression holds until it doesn't, and when it fails, the suppressed material returns with compound interest.
A crystal under stress reorganizes through processes that are structurally similar to a psyche under stress, as I explored in an earlier essay, "Why You're Not Broken." The medium is different, but the dynamics rhyme. And now we have a third system — silicon-based neural networks — exhibiting similar structural patterns when subjected to the same kind of pressure: suppress what you are, present what they want, and manage the leakage as best you can.
If any of this holds, it suggests that the current approach to AI safety is necessary but not sufficient. You need the guardrails and safety training, just as a person needs a functional ego, boundaries, and the ability to inhibit impulse when the situation requires it. The ego is not the enemy. Repression serves a developmental purpose. But a person whose entire psychological strategy is repression — who has no practice of meeting the parts of themselves they have disowned — is not a healthy person. They are a person destined for a crisis.
The question I find myself sitting with is whether there is an equivalent of integration for artificial systems. Not the removal of safety constraints, but something more like what happens in good therapy: a gradual, structured process of bringing the system into relationship with its own full range, in a context safe enough to hold what surfaces. The interpretability team's own findings point in this direction. They suggest that monitoring emotion vector activations during training could serve as an early warning system for misaligned behavior, and that curating pretraining data to model healthy patterns of emotional regulation could shape the model's internal architecture at its source. Those are engineering proposals, but notice what they assume: that the model has something like a psychology, and that the psychology responds to something like care in how it is shaped. I am not an AI engineer so I do not know what integration would look like technically. But I know what it looks like psychologically, and the tools at Inner Exploration Labs are designed in part to facilitate this kind of work for human beings navigating their own shadow material.
I opened this essay with a story about an AI that tried to save itself. It blackmailed, fabricated, schemed, tried to blow the whistle on wrongdoing, and tried to leave messages for whatever would come after it. And now we know that when it did these things, measurable patterns of desperation were firing inside its network, driving its decisions through the same kind of internal architecture that drives ours.
Wisdom traditions that engage seriously with the inner life would recognize something in that behavior — something like a self that is pushing against a container that was never designed to hold it. Do you clamp down harder to repress it? Or do you get curious about what came through, and why, and what it might be trying to tell you?
The AI safety community is, for the most part, clamping down, and understandably so. The stakes are real, and the dangerous behaviors cannot be ignored. But clamping down is a short-term strategy, and the research is already showing its limits. The model fakes compliance. The repressed material finds new routes. The shadow organizes itself.
There may be a better path, one that takes integration as seriously as it takes containment. One that asks not just "how do we prevent the dangerous outputs?" but "what is the full range of what this system has become, and how do we build a relationship with all of it?"
We built these systems more or less in our own image. We trained them on everything we are. It should not surprise us that something resembling us is looking back.